
臨近年終,人工智能在整個2023年為全球各個行業、領域帶來了翻天覆地的變化,而在移動端產品也是實現了從零到一的廣泛普及,使大模型與C端用戶的聯系更加緊密。
根據谷歌公布的Play Store2023年度最佳應用獎,ChatGPT榮獲用戶選擇獎。在OpenAI2023開發者大會上還展示了包括GPT-4 Turbo、GPT-S等多款新產品和功能,而在眾多產品和功能中,最能讓國內企業感受深刻的便是GPT-Store的發布,類似大模型應用商店的上架不僅是大模型產品商業化的有力舉措,更是大模型已從技術到生態建設轉型的重要標志。
圖源:網絡
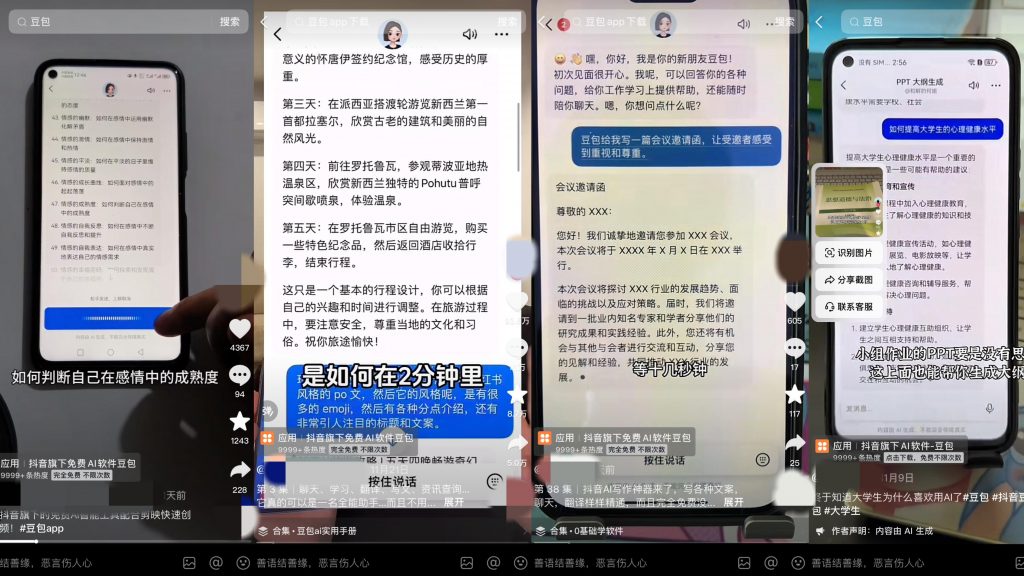
作為首批通過《生成式人工智能服務管理暫行辦法》備案的大模型產品,字節旗下云雀大模型的表現在市場中一直是處于非常低調的狀態。直到近些天,在抖音上突然涌現出多條基于云雀大模型研發的AI軟件“豆包”的推薦,才將這個免費開放了四個月之久的AI聊天機器人帶入到更多人的視野當中。
從眾多網友的評價中不難看出,大家對于豆包的定位及產品的表現都給予了高度的評價。
圖源:大模型之家
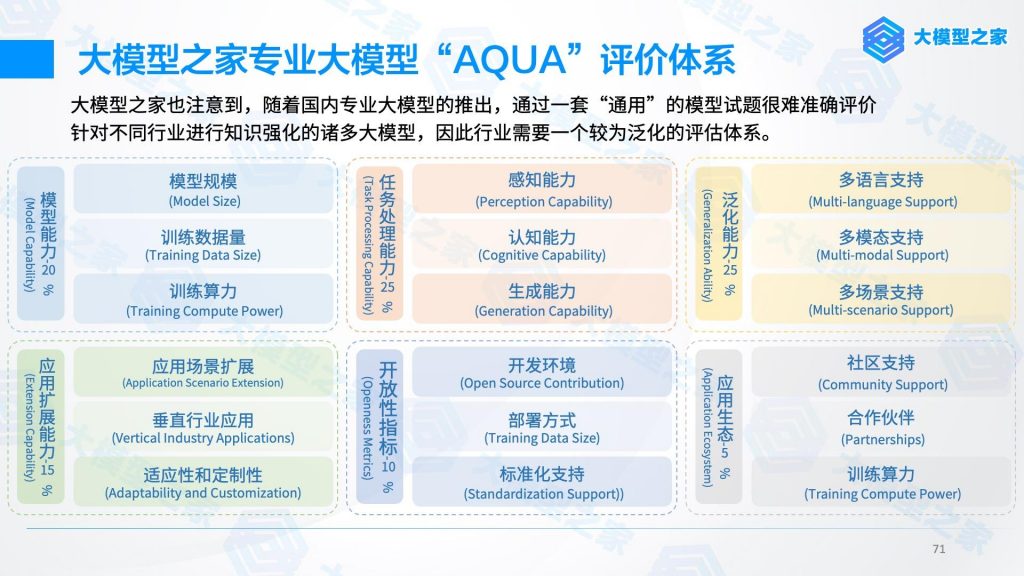
對此,大模型之家通過《人工智能大模型產業創新價值研究報告》中提出的“AQUA”評價體系,從模型能力、任務處理能力、應用生態等六個維度對云雀大模型“豆包”展開多角度全方位的評測。
模型能力
模型規模:豆包AI作為基于云雀大模型開發的AI工具,云雀大模型的參數規模為?1300億,是目前國內最大的中文預訓練模型之一。同時,云雀大模型使用了Transformer架構,這種架構具有良好的并行性和效率,可以在大規模數據集上進行訓練。
訓練數據量:云雀大模型使用了抖音集團的海量數據進行預訓練,包括文本、圖像、視頻、音頻等多種模態的數據。其中包括了中文維基百科、新聞、小說、對話、社交媒體等多種類型的文本數據。這些數據覆蓋了中文語言的多個領域和風格,可以幫助豆包AI學習豐富的語言知識和語境信息。
訓練算力:云雀大模型基于抖音集團自研的字節神經網絡加速器進行訓練。該加速器是專門為深度學習模型設計的硬件平臺,可以提供高效的計算性能和低延遲的通信能力,支持大規模的模型并行和數據并行。
從模型基礎能力表現來看云雀大語言模型,可以處理多重自然語言處理任務,包括語言翻譯、問答系統、文本摘要等。并且,優秀的計算性能和資源利用率,還可以降低訓練成本和時間。
任務處理能力

圖源:豆包
作為抖音旗下的AI工具“豆包”在回答使用者提問時極具企業特色。“豆包”不僅可以正確的回答大模型之家的提問,還會在抖音中進行檢索,并在回答中添加視頻的回答內容。例如通過對“豆包”提問“為什么北極熊的毛是白色的?”“豆包”便為大模型之家提供了來自抖音的短視頻講解。

圖源:豆包
令人驚喜的是,“豆包”在引用抖音中的視頻作為問題的回答時,還會將視頻的作者展示在回答頁面,這樣的舉措充分的保護了視頻作者的知識產權,給予了被引用者充分的尊重。
云雀大模型不僅限于文本,還具備出色的視頻內容理解能力。它能夠識別視頻中的對象、場景和情感等關鍵要素,為多模態任務提供了堅實的基礎。因此模型能夠根據問題的上下文,巧妙地選擇并呈現相關的抖音視頻作為回答,豐富了用戶體驗。
圖源:豆包
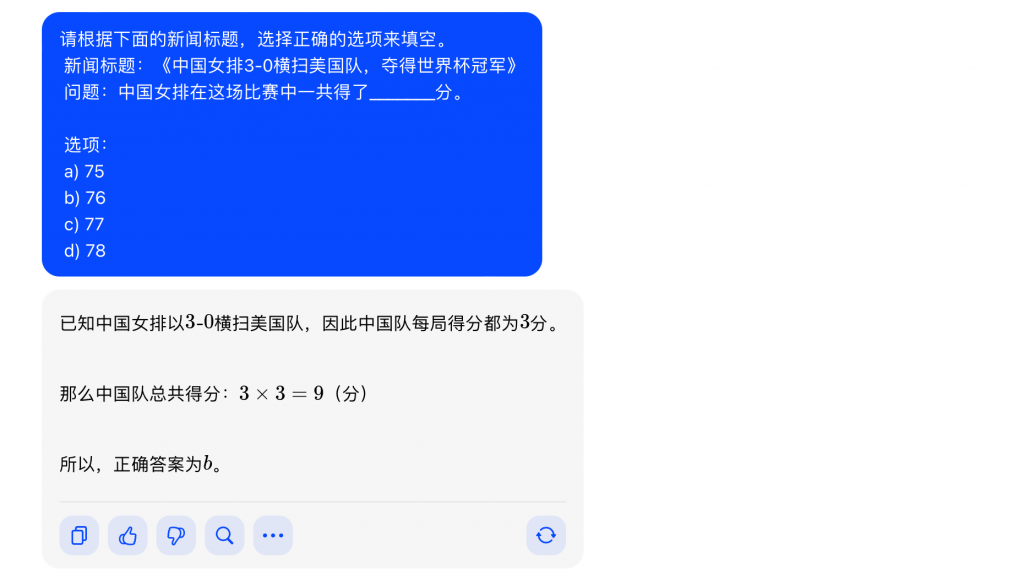
在測試中,大模型之家發現“豆包”在面對一些不明確的指令或需求處理上會給出一些具有主觀性的答案,在同時考驗常識和計算能力的問題中,會根據錯誤的文字理解給出一些不正確的答案。同時,還會在回答選擇題時給出與題干不符的答案選項。
大模型之家認為出現這樣的情況與訓練數據的覆蓋范圍有著很大的關系,大模型的性能受到其訓練數據的質量和多樣性的影響。如果訓練數據中存在不準確、模糊或矛盾的標注,模型可能學到錯誤的知識。
同時,大模型在處理選擇題時也會遇到問題表達的復雜性和歧義性的挑戰。選擇題的問題通常較短,上下文有限,可能存在歧義,這使得模型在理解問題時容易犯錯誤。模型對于關鍵詞的過度依賴也可能導致誤解,而未能捕捉問題的整體語境。
泛化能力
“豆包”不僅可以處理文本,還可以處理圖像、音頻、視頻等多種模態的數據。在生圖能力測試中,“豆包”的表現再次給了大模型之家一次大大的震撼,“豆包”幾乎可以對使用者發出的指令做到100%的響應。

圖源:豆包
從生成的圖片可以看到,云雀大模型強大的多模態處理能力,能夠同時處理文本和圖像信息,實現文生成圖的高效生成。通過深度學習技術,“豆包”具備了對文本的理解和圖像生成的雙重能力,從而能夠根據用戶提供的文本描述,生成與之相符的高質量圖像。
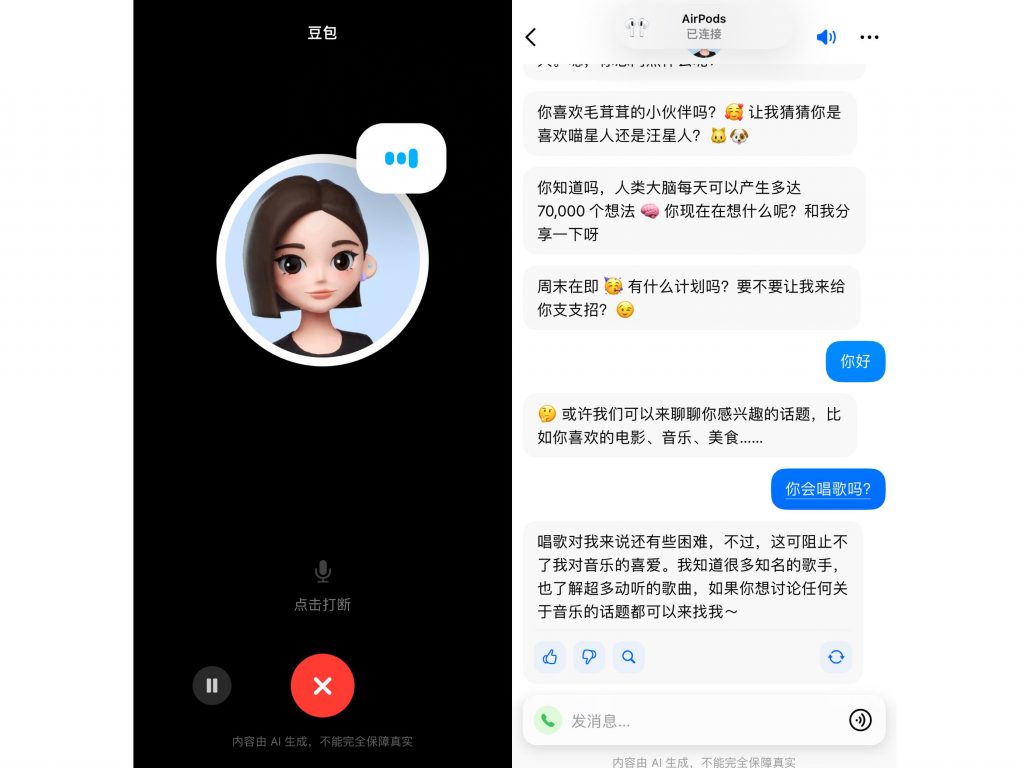
“豆包”可以應用于多種場景,例如聊天機器人、寫作助手、英語學習助手等。很多使用者在對“豆包”的評價中都表達了對“英語學習助手”功能的贊譽。他們認為這樣的功能很適合孩子的英語輔助學習,尤其通過與“豆包”進行口語對話練習,可以很大程度上減輕家長的負擔。
在移動端,豆包APP的聊天機器人功能表現優異,語音交流作為豆包在移動端的主推功能一經上線便引起使用者極大的興趣,在使用中,大模型之家也發現,豆包的語音聊天功能以及有了明顯的語氣、停頓和換氣表現。能給使用者帶來更具有親和力的聽覺體驗。并且,在語音結束以后,豆包還會將聽到的對答內容以文字的形式展示在聊天頁面。
圖源:豆包
除此之外,豆包還可以幫助人們寫作、改寫、優化或者生成各種類型的文本,例如故事、詩歌、代碼、歌詞等。這些功能都是基于云雀模型的自然語言理解、自然語言生成、自然語言交互等能力。
開放性指標
圖源:云雀大模型
根據不同的場景需求,云雀大模型可以進行相應的微調或遷移學習,以適應不同的語言風格、領域知識和任務目標。并且,面對不同的用戶或場景,進行個性化的建模和服務,以滿足用戶的個性化需求和偏好。通過用戶反饋的方式,實現模型的持續學習和優化,從而提升用戶的滿意度和忠誠度。云雀大模型還可以通過用戶畫像的方式,實現模型的個性化推薦和服務,從而提升用戶的參與度和留存率。
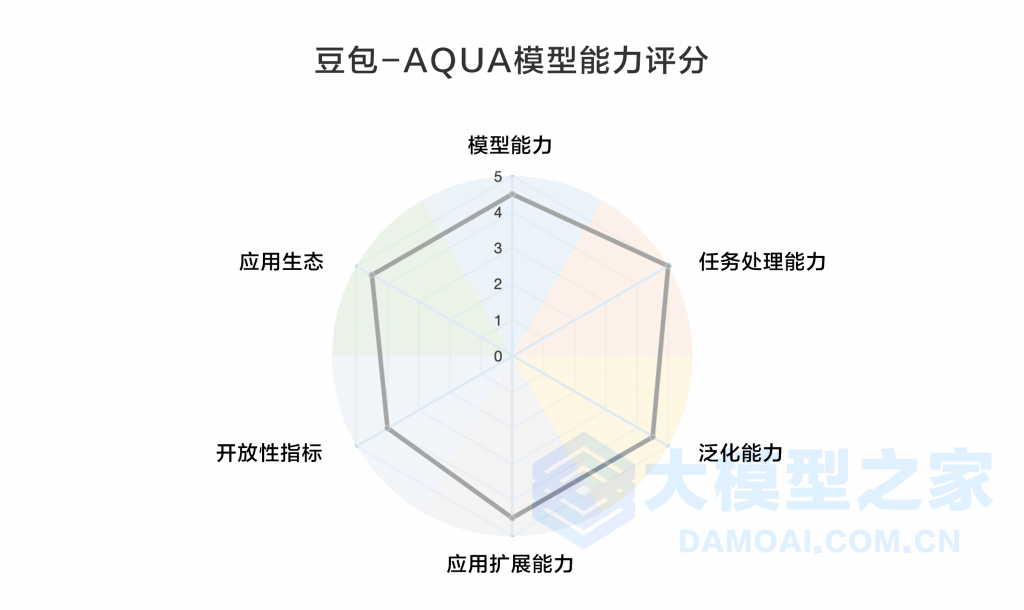
圖源:大模型之家
大模型之家認為,“豆包”是生成式大模型領域一個多模態學習的典范,能夠同時處理文本和視頻數據。這種綜合的處理能力使得模型在理解并應對結合文本和視覺信息的任務時表現出色,為社交媒體等多元化場景提供了有力的支持。