速途網(wǎng)訊 今日,小米在Xiaomi MiMo官微宣布,正式開源首個原生端到端語音模型——Xiaomi-MiMo-Audio,它基于創(chuàng)新預(yù)訓(xùn)練架構(gòu)和上億小時訓(xùn)練數(shù)據(jù),首次在語音領(lǐng)域?qū)崿F(xiàn)基于 ICL 的少樣本泛化,并在預(yù)訓(xùn)練觀察到明顯的“涌現(xiàn)”行為。
官方稱Xiaomi-MiMo-Audio的突破帶來了語音領(lǐng)域的 “GPT-3 時刻”。該模型首次證明把語音無損壓縮預(yù)訓(xùn)練 Scaling 至 1 億小時可以“涌現(xiàn)”出跨任務(wù)的泛化性,表現(xiàn)為 Few-Shot Learning 能力。(編輯:李美涵)
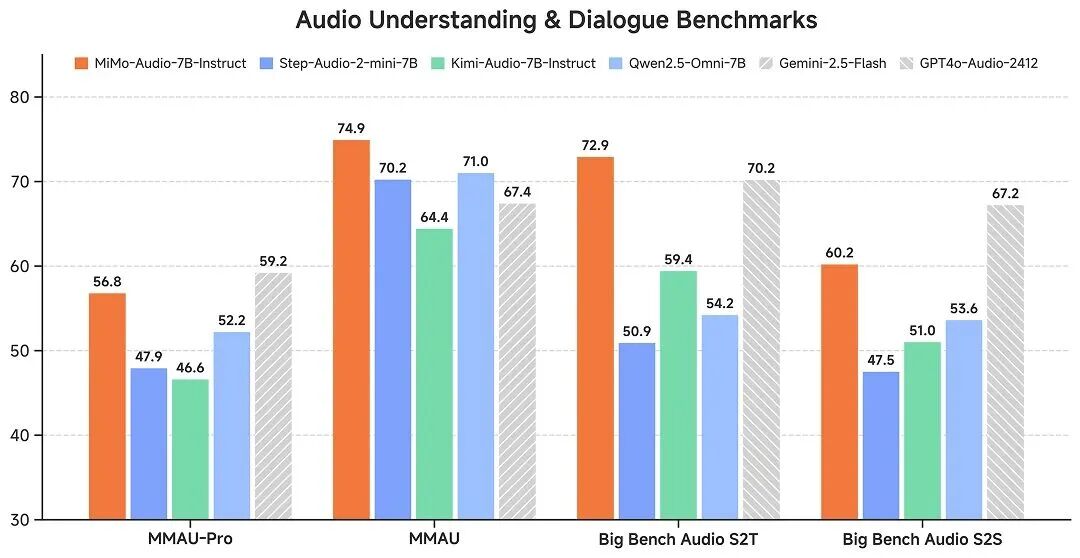
Xiaomi-MiMo-Audio性能強悍,具體表現(xiàn)如下:
1.在通用語音理解及對話等多項標(biāo)準(zhǔn)評測基準(zhǔn)中,MiMo-Audio 大幅超越了同參數(shù)量的開源模型,取得 7B 最佳性能
2.在音頻理解基準(zhǔn) MMAU 的標(biāo)準(zhǔn)測試集上,MiMo-Audio 超過 Google 閉源語音模型 Gemini-2.5-Flash
3.在面向音頻復(fù)雜推理的基準(zhǔn) Big Bench Audio S2T 任務(wù)中,MiMo-Audio 同樣超越了 OpenAI 閉源的語音模型 GPT-4o-Audio-Preview
模型開源地址:https://huggingface.co/XiaomiMiMo/MiMo-Audio-7B-Base
技術(shù)報告:https://github.com/XiaomiMiMo/MiMo-Audio/blob/main/MiMo-Audio-Technical-Report.pdf